You can move the report server databases that are used in a current installation to a SQL Server Database Engine instance that is on a different computer. Both the reportserver and reportservertempdb databases must be moved or copied together. A Reporting Services installation requires both databases; the reportservertempdb database must be related by name to the primary reportserver database you are moving.
Moving a database does not effect scheduled operations that are currently defined for report server items.
Moving a database does not effect scheduled operations that are currently defined for report server items.
- Schedules will be recreated the first time that you restart the Report Server service.
- SQL Server Agent jobs that are used to trigger a schedule will be recreated on the new database instance. You do not have to move the jobs to the new computer, but you might want to delete jobs on the computer that will no longer be used.
- Subscriptions, cached reports, and snapshots are preserved in the moved database. If a snapshot is not picking up refreshed data after the database is moved, clear the snapshot options in Report Manager, click Apply to save your changes, re-create the schedule, and click Apply again to save your changes.
- Temporary report and user session data that is stored in reportservertempdb are persisted when you move that database.
 Important Important |
|---|
| The steps provided in this topic are recommended when relocating the report server database is the only change you are making to the existing installation. Migrating an entire Reporting Services installation (that is, moving the database and changing the identity of the Report Server Windows service that uses the database) requires connection reconfiguration and an encryption key reset. For more information about migrating a Reporting Services installation, see Migration (Reporting Services)1. |
If you can take the report server offline, you can detach the databases to move them to the SQL Server instance you want to use. This approach preserves permissions in the databases. If you are using a SQL Server 2008 database, you must move it to another SQL Server 2008 instance. After you move the databases, you must reconfigure the report server connection to the report server database. If you are running a scale-out deployment, you must reconfigure the report server database connection for each report server in the deployment.
Use the following steps to move the databases:
Use the following steps to move the databases:
- Backup the encryption keys for the report server database you want to move. You can use the Reporting Services Configuration tool backup the keys.
- Stop the Report Server service. You can use the Reporting Services Configuration tool to stop the service.
- Start SQL Server Management Studio and open a connection to the SQL Server instance that hosts the report server databases.
- Right-click the report server database, point to Tasks, and click Detach. Repeat this step for the report server temporary database.
- Copy or move the .mdf and .ldf files to the Data folder of the SQL Server instance you want to use. Because you are moving two databases, make sure that you move or copy all four files.
- In Management Studio, open a connection to the new SQL Server instance that will host the report server databases.
- Right-click the Databases node, and then click Attach.
- Click Add to select the report server database .mdf and .ldf files that you want to attach. Repeat this step for the report server temporary database.
- After the databases are attached, verify that the RSExecRole is a database role in the report server database and temporary database. RSExecRole must have select, insert, update, delete, and reference permissions on the report server database tables, and execute permissions on the stored procedures. For more information, see How to: Create the RSExecRole2.
- Start the Reporting Services Configuration tool and open a connection to the report server.
- On the Database page, select the new SQL Server instance, and then click Connect.
- Select the report server database that you just moved, and then click Apply.
- On the Encryption Keys page, click Restore. Specify the file that contains the backup copy of the keys and the password to unlock the file.
- Restart the Report Server service.
If you cannot take the report server offline, you can use backup and restore to relocate the report server databases. You should use the ‘Copy_Only’ option. Beginning in SQL Server 2008, SQL Server Management Studio supports copy-only backups. After you restore the databases, you must configure the report server to use the database on the new server instance. For more information, see the instructions at the end of this topic.
Using BACKUP and COPY_Only to Backup the Report Server Databases
When backing up the databases, set the COPY_Only option and backup type to Full.
For more information on using SQL Server Management Studio to backup a database, see How to: Back Up a Database (SQL Server Management Studio)3
| Note |
|---|
| Be sure to back up both the ReportServer and ReportServerTempDB databases as well as their associated log files. |
Using RESTORE and MOVE to Relocate the Report Server Databases
When restoring the databases, you can Use the RESTORE WITH NORECOVERY argument to perform the initial restore; this keeps the database in a restoring state, giving you time to review log backups to determine which one to restore. You would then repeat the RESTORE operation but use the RESTORE WITH RECOVERY argument.
For more information on using SQL Server Management Studio to restore a database, see How to: Restore a Database Backup (SQL Server Management Studio)4
| Note |
|---|
| Be sure to restore both the ReportServer and ReportServerTempDB databases as well as their associated log files. |
How to Configure the Report Server Database Connection
- Start the Reporting Services Configuration tool and open a connection to the report server.
- On the Database page, click Change Database. Click Next.
- Click Choose an existing report server database. Click Next.
- Select the SQL Server that now hosts the report server database and click Test Connection. Click Next.
- In Database Name, select the report server database that you want to use. Click Next.
- In Credentials, specify the credentials that the report server will use to connect to the report server database. Click Next.
- Click Next and then Finish.
| Note |
|---|
| A Reporting Services installation requires that the SQL Server Database Engine instance include the RSExecRole role. Role creation, login registration, and role assignments occur when you set the report server database connection through the Reporting Services Configuration tool. If you use alternate approaches (specifically, if you use the rsconfig.exe command prompt utility) to configure the connection, the report server will not be in a working state. You might have to write WMI code to make the report server available. For more information, see Reporting Services WMI Provider5. |
Tasks
Reference
Concepts
source: http://technet.microsoft.com/en-us/library/ms156421.aspx

 Figure 1: AdventureWorks tables with schemas.
Figure 1: AdventureWorks tables with schemas. 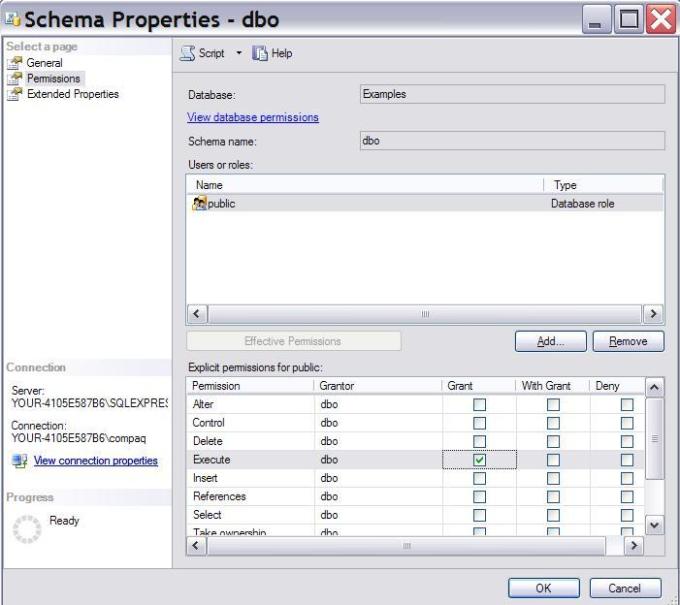 Figure 2: Grant execute permission on all stored procedures in the schema.
Figure 2: Grant execute permission on all stored procedures in the schema.